
From Batch to Real-Time: How LinkedIn Serves Recommendations
LinkedIn: Four-Phase Recommendation System Evolution (90% Cost Reduction)

When you open LinkedIn and instantly see personalized jobs or profile suggestions, you’re seeing the outcome of four distinct architectural eras. Each era reflects a deliberate trade-off between freshness, latency, cost, and model power.
This evolution is less about optimization, and more about knowing when an architecture has hit its ceiling.
The Core Problem (That Never Changes)
Given millions of items, how do you return the most relevant ones for a user in ~100ms at global scale?
Key constraints:
Freshness: React to recent user behavior
Latency: Stay within tight p99 budgets
Cost: Avoid computing and storing things no one sees
Model complexity: Support increasingly powerful ML models
Every architecture answers these constraints differently.
The Four Phases of Recommendation Architecture
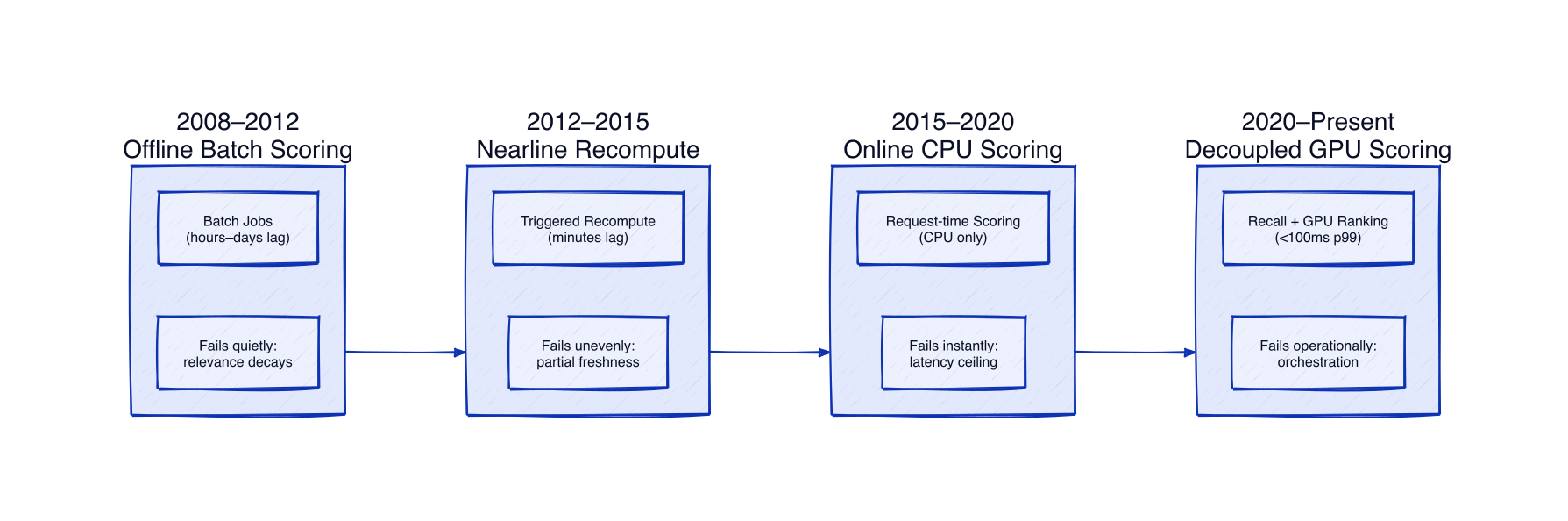
Phase 1: Offline Batch Scoring (2008–2012)
In the earliest phase, LinkedIn relied on offline batch jobs that precomputed recommendation scores and stored them for lookup.
This approach failed quietly. Storage requirements exploded as users and items grew, and recommendations became stale almost immediately. Profile updates or job changes took hours or days to appear.
Why this matters?
Offline systems don’t usually break. They decay. Relevance fades slowly, and by the time metrics move, the architecture is already holding you back.
Phase 2: Nearline Scoring (2012–2015)
To reduce staleness, LinkedIn introduced nearline recomputation triggered by user actions.
Freshness improved, but consistency didn’t. Some recommendations were updated quickly while others lagged behind. Distributed triggers introduced coordination complexity and partial failures that were hard to observe.
Why this matters?
Hybrid systems often look like progress, but they introduce uneven behavior that’s harder to debug than full batch or full real-time systems.
Phase 3: Online Scoring on CPUs (2015–2020)
The next shift moved scoring into the request path. Recommendations were generated and scored in real time when a user loaded a page.
Freshness was solved, but latency became the dominant constraint. With a strict end-to-end budget, models had to be simple enough to run on CPUs. Feature richness and model depth were limited, and cold-start problems persisted.
Why this matters?
Online scoring fixes staleness, but it puts a ceiling on intelligence. Latency budgets become product constraints.
Phase 4: Decoupled Architecture with Remote GPU Scoring (2020–Present)
The current system separates candidate generation from scoring and offloads inference to remote GPU services.
This architectural split changed what was possible. Candidate generation focused on recall, while scoring models could grow far more sophisticated. Embedding-based retrieval enabled semantic matching, reducing cold-start issues.
Why this matters?
GPUs didn’t just make models faster—they made entirely new classes of models possible.
What Happens in a Single Request
When a user opens LinkedIn Jobs, the system generates candidates from multiple sources, narrows them using embedding similarity, and ranks them using GPU-powered models. Hundreds of features and real-time context are evaluated, all within roughly 100 milliseconds at the 99th percentile.
Decoupling recall from ranking allows each stage to evolve independently without blowing the latency budget.
Cost and Failure Modes
Despite GPU infrastructure being expensive, overall system cost dropped dramatically. The system stopped precomputing and storing scores that were never viewed and shifted to on-demand inference.
Failure modes shifted as well. Offline systems fail slowly through staleness. Online systems fail instantly through latency. GPU-based systems fail operationally through serving and orchestration complexity.
Every architectural upgrade trades one kind of risk for another. Maturity isn’t eliminating failures, it’s choosing the ones you can handle.
Choosing the Right Architecture
This evolution isn’t linear progress where the final stage is always best.
Offline batch systems still make sense at small scale. Nearline or online scoring becomes necessary when staleness hurts engagement. GPU-based inference only pays off when traffic, latency pressure, and business value align.
Premature architectural ambition is just another form of technical debt.
The Real Takeaway
LinkedIn’s biggest gains didn’t come from tuning models, but they came from recognizing architectural limits and crossing them decisively.
If your system feels stuck despite constant optimization, the problem is probably architectural, not algorithmic.
Learn more about ML design concepts on System Overflow.