
How Airbnb Built Adaptive Traffic Management for a Multi-tenant Key-value Store
Designing layered, adaptive QoS and rate limiting for multi-tenant backend services using resource-aware controls and local feedback loops.

Introduction
Every request you make at Airbnb - from searching for a stay to loading support data - eventually hits Mussel, Airbnb’s multi-tenant key-value store. At normal load it serves millions of reads smoothly, but during spikes, bulk uploads, or bot traffic, it has to stay fast without taking the rest of the platform down.
Airbnb’s first solution used simple per-client QPS limits. That was enough to prevent total meltdowns, but not enough to maximize useful work while staying within capacity. The real challenge was building adaptive traffic management that reacts to changing workloads in real time.
In this article, you will see how Airbnb evolved Mussel from static rate limiting to a layered QoS system, and how you can apply the same patterns - resource-aware limits, local feedback control, and hot-key protection - in your own systems.
The Challenge
Mussel sits in front of a storage engine as a fleet of stateless dispatcher pods running on Kubernetes. Every online product area at Airbnb sends traffic to it: point lookups, range scans, bulk writes, and internal tools. On top of normal diurnal cycles, Mussel also sees:
- Sudden user spikes, for example when a listing goes viral
- Large analytical or backfill jobs that scan huge ranges
- Misbehaving crawlers or outright DDoS-like bursts
The original design used a Redis-backed rate limiter: each caller had a static per-minute quota, and dispatchers incremented a counter per request. If you exceeded your quota, Mussel returned HTTP 429. This was simple and gave caller-level isolation: one bad client could not take the entire system down.
Over time, two deeper problems appeared.
1. Cost variance between requests
A one-row read and a 100,000-row range scan both counted as “1 request”. In reality they could differ by orders of magnitude in:
- CPU and memory usage
- Network bytes
- Disk I/O and cache pressure
This meant you could stay within your QPS but still quietly crush the backend with a few very expensive queries. The system had no concept of real resource cost per request.
2. Traffic skew and hot spots
Rate limits were per caller, not per data item. Imagine a popular listing that appears on a front page. Thousands of different callers all read the same key. Each caller respects its quota, but all these reads pound a single shard. That shard slows down, and now even unrelated keys hosted there get slow. Isolation at the caller level did not give isolation at the data or shard level.
A useful analogy is a supermarket with a “10 items per customer” rule but no control on how many people swarm one shelf. You avoid one person hogging the checkout, but if 500 people all grab from the same shelf at once, that aisle still collapses.
Common solutions like global QPS caps or static per-service quotas fail here because they:
- Do not distinguish cheap from expensive work
- Do not respond quickly enough to micro-bursts and hot keys
- Do not express priority across different types of traffic
This is a common challenge whenever you run a multi-tenant backend that serves heterogeneous workloads: databases, search clusters, caches, or shared internal platforms. You are not just limiting how many calls arrive; you are managing which work gets done under constrained resources.
Airbnb’s Solution Architecture
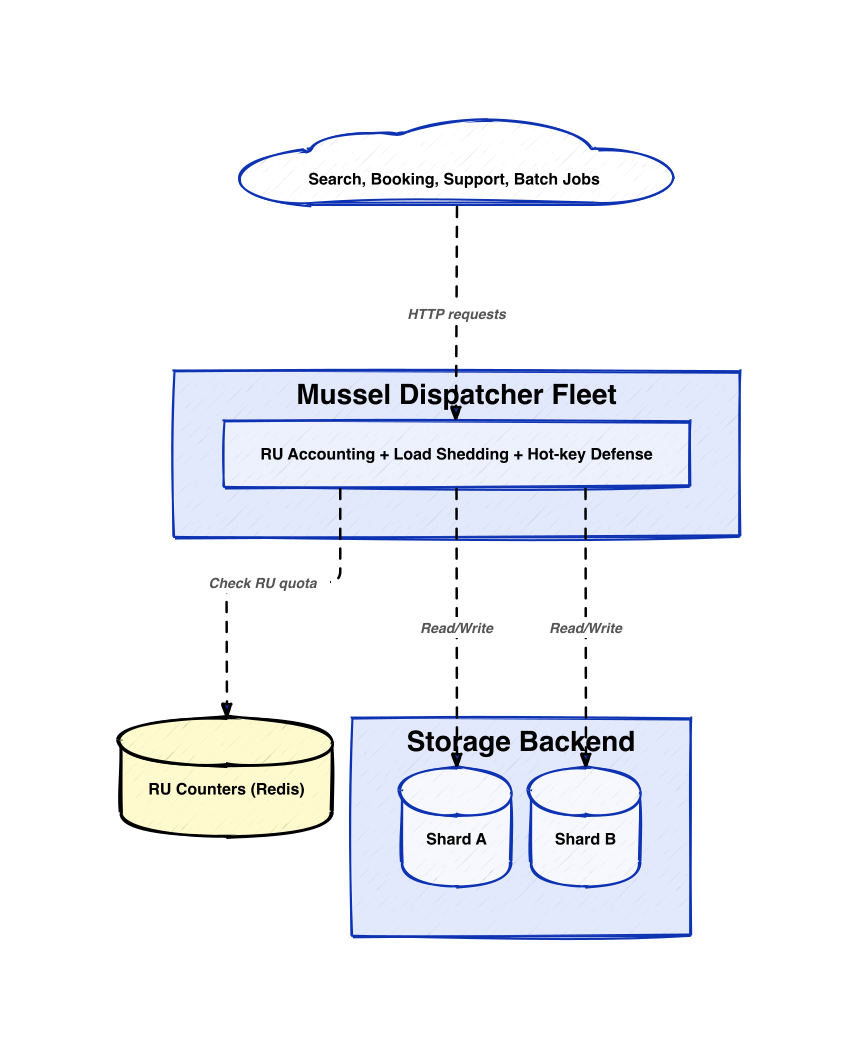
Airbnb’s engineers redesigned Mussel’s QoS as a layered control system rather than a single global rate limit. The layers are:
1. Resource-aware rate control (RARC) using request units
2. Load shedding based on latency feedback and request criticality
3. Hot-key detection and mitigation to protect shards from skewed access
You can read this as: “price requests correctly, then adapt to stress, then neutralize amplification patterns.” Here is how each layer works and how it generalizes.
1. Resource-aware rate control with request units
Instead of counting raw QPS, Mussel now charges each operation in request units (RU). An RU is a synthetic cost metric that reflects:
- A base cost per call
- Data volume (rows or bytes)
- Observed latency for that call
You can think of this as a linear pricing model:
> RU = base_cost + weight_bytes bytes + weight_latency latency_ms
Weights are calibrated from load tests that roughly balance CPU, network, and disk cost. The exact coefficients are not the important part. The important idea is that expensive operations consume more of a client’s quota than cheap ones, using metrics you can easily observe at the proxy.
Each caller now has a static RU quota per time window, not a raw QPS quota. Each dispatcher maintains a local token bucket: on each request, it computes the RU cost and decrements tokens. When tokens are gone, Mussel rejects the request with a throttling code.
Airbnb chose this model because it preserved a simple, static contract to clients (you get N RU per minute), while internally allowing much better fairness across workloads. This pattern - “convert requests into resource units, then rate limit on units” - is useful any time you have:
- A shared backend with variable-cost operations
- The ability to measure simple per-request features
2. Load shedding with local latency feedback
RU-based quotas smooth average behavior, but they do not react instantly to rapid changes. Airbnb added a load-shedding layer that uses two local signals inside each dispatcher:
- A latency ratio: short-term p95 latency divided by long-term p95 latency
- A queue delay threshold: based on how long requests spend waiting in the dispatcher thread pool
The latency ratio is a compact way to detect when the system is getting slower. A ratio near 1 means “steady.” If the short-term p95 grows sharply, the ratio drops toward 0.3 or lower. When it crosses a threshold, the dispatcher concludes “we are entering overload” and starts to penalize less critical traffic classes by artificially inflating their RU cost or dropping queued requests earlier.
The queue control is inspired by CoDel-style algorithms that do not just look at queue length, but at sojourn time (how long each request sat in the queue). If that wait time exceeds a target for long enough, the dispatcher starts failing new arrivals quickly instead of letting them pile up and time out.
Airbnb also tags traffic with criticality tiers (for example, user-facing vs batch). Under stress, lower tiers back off first, preserving headroom for critical paths like customer support or trust and safety.
This pattern of local, feedback-based load shedding is powerful when you need to:
- React within milliseconds to backend slowdowns
- Protect high-priority workloads without human intervention
- Keep the control logic independent per proxy instance
3. Hot-key detection and DDoS mitigation
Even with good rate limits, a “stampede” of reads for one record can overload its shard. Airbnb addressed this with a three-part hot-key defence at each dispatcher:
1. Real-time top-k tracking of keys using a constant-space streaming algorithm
2. Short-lived local caching of hot keys
3. Request coalescing for in-flight reads of the same hot key
Every incoming key updates a compact data structure that approximates the most frequent keys. When a key crosses a hotness threshold, the dispatcher starts serving it from a small process-local LRU cache with a very short TTL (on the order of seconds). This is enough to ride out a news spike or a bot burst without requiring a global cache.
If multiple requests for a hot key arrive while a cache miss is in progress, the dispatcher records that there is an in-flight request and attaches new callers to the same future. When the backend response arrives, it fans out to all waiters. In practice this means that for each dispatcher pod, at most one in-flight backend request per hot key is active at a time.
This general pattern - “detect hot keys, cache locally with tiny TTLs, coalesce in-flight requests” - is broadly applicable to any key-based storage or cache. It converts N identical expensive reads into 1 read plus N cheap local responses.
Trade-offs & Considerations
Airbnb’s approach trades simplicity for control and resilience.
On the positive side, you get:
- Finer-grained fairness: heavy range scans cannot starve cheap point reads
- Better protection of critical paths during overloads
- Robustness to traffic skew and DDoS-style patterns
On the cost side, you accept:
- More moving parts: RU accounting, latency feedback, queue control, top-k tracking, local caches
- Tuning complexity: choosing RU weights, latency thresholds, and hot thresholds
- Some approximation error: RU formulas and streaming algorithms are not perfect
This architecture works best when:
- You own a clear proxy or gateway where all traffic passes
- You can cheaply measure basic per-request metrics (bytes, latency)
- You have heterogeneous workloads and multi-tenant usage
It may be overkill for a small service with uniform traffic where simple per-client QPS limits suffice, or for systems where you cannot easily change client quotas or introduce admission control.
You also need to think about failure modes: what happens if the central quota store (like Redis) is down, or if latency metrics get corrupted, or if hot-key detection misfires. Airbnb’s design keeps most control loops local to each dispatcher, which reduces blast radius: if one node’s control logic behaves badly, it does not directly affect others.
Conclusion
Airbnb’s evolution of Mussel from static QPS limits to adaptive traffic management illustrates a powerful system design pattern for multi-tenant backends.
You start by measuring work in resource units, not requests. You then layer fast, local feedback loops to shed load based on latency and queue health. Finally, you neutralize amplification patterns like hot keys with detection, caching, and request coalescing.
If you run a shared data service, cache, or API that different teams depend on, these ideas map directly to classic system design concepts: token buckets and RU-based rate limiting, admission control, backpressure, prioritized QoS, and hotspot mitigation. As your traffic and tenants grow, this style of architecture can be the difference between “we stayed up” and “everything was technically within quota but still fell over.”
Loved the explanation! Especially, the importance local decision making.