
How Dropbox Designed Evaluation-First Infrastructure for Conversational AI
Using Dropbox Dash as a case study to design datasets, metrics, and evaluation platforms that gate LLM deployments like CI.

Most teams evaluate LLM applications the way they evaluated traditional ML: compute an accuracy score, eyeball some examples, and ship. Then production hallucinations start appearing, and nobody can trace which change caused them.
Dropbox faced this problem with Dash, their conversational AI that answers questions about files, wikis, and connected tools. Their solution was to treat evaluation as infrastructure, not an afterthought. This article breaks down how they designed it.
Why Traditional Metrics Failed
Dash is not a single model. It is a pipeline:
user query → intent classification → document retrieval → ranking → prompt construction → LLM inference → safety filtersEach stage is non-deterministic. Changing retrieval parameters alters which documents reach the model. That interacts with the prompt template. Which affects how often the model cites sources correctly. You cannot reason about quality by looking at any component in isolation.
Early on, Dropbox engineers relied on classic NLP metrics: BLEU, ROUGE, BERTScore, embedding similarity. These measure surface overlap or semantic proximity, not production correctness.
The core problem: A high ROUGE score can hide a hallucinated filename. Strong embedding similarity can correspond to an answer that ignored the question. These metrics cannot answer: did the response actually come from the user’s documents? Were claims supported by retrieved context? Were the correct files cited?
As soon as Dropbox tried to use these metrics to gate real deployments, they broke down.
The Flight Control Analogy
Consider how you would certify a new autopilot system. You would never approve it only by checking that steering roughly matches a reference trajectory. You also need alarms for altitude, fuel, structural stress, and dozens of other dimensions.
An LLM evaluation system works the same way. It must be a network of alarmed checks, not a single similarity score. Quality is multi-dimensional and context-dependent, but your system must compress it into automated checks that decide whether a change can ship.
Dropbox had additional constraints:
Evaluate on both public benchmarks and Dropbox-specific content
Every model, retriever, or prompt change must behave like production code with tests wired into CI
Scale evaluation to many experiments without drowning in manual labeling
The Three-Layer Architecture
Dropbox built an evaluation platform that wraps the LLM application. It has three layers: curated datasets, LLM-powered metrics, and a CI-integrated orchestration platform.
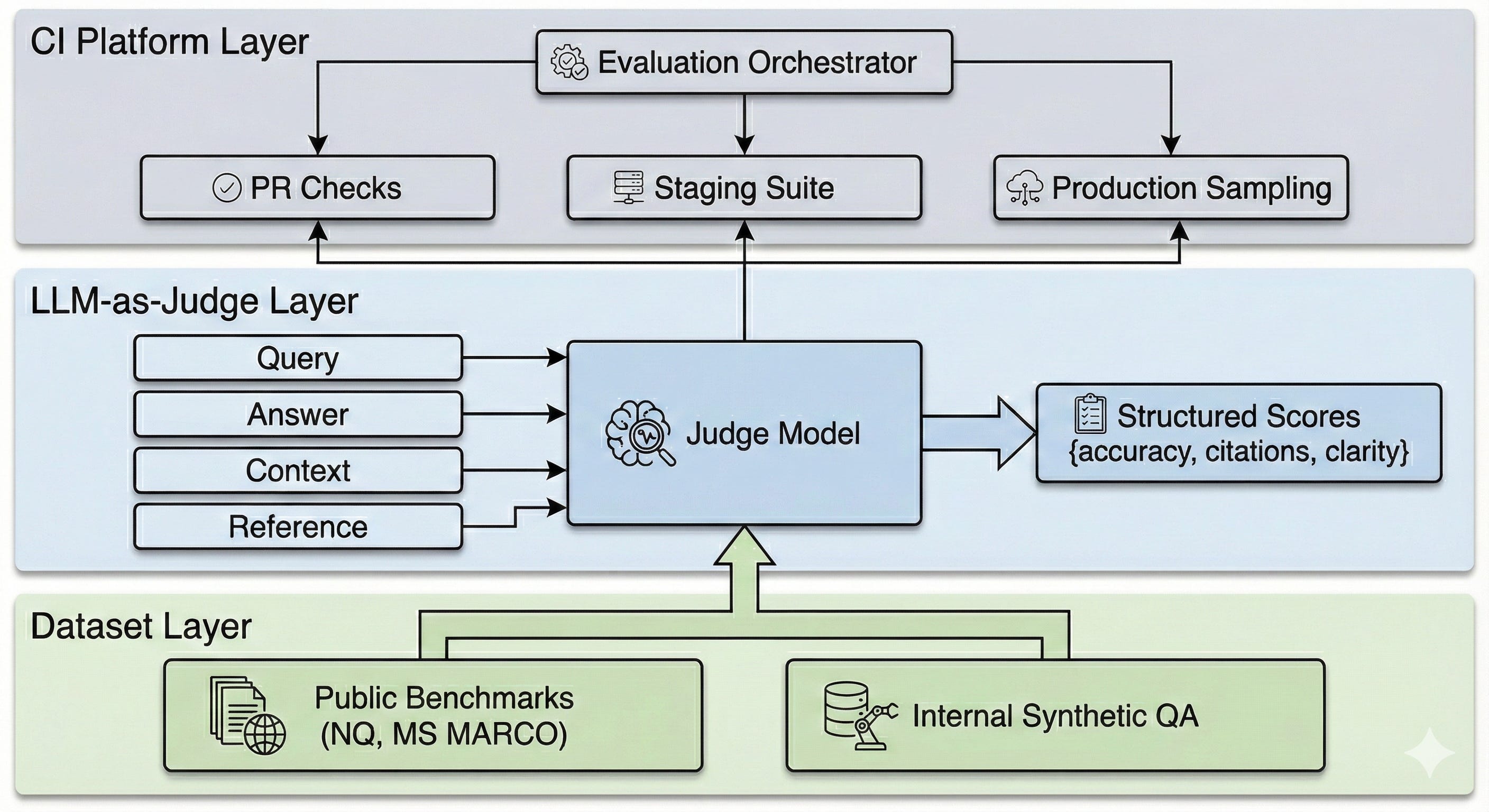
Layer 1: Dataset Curation
Dropbox combined two sources:
Public QA datasets. Natural Questions, MS MARCO, and MuSiQue stress-test retrieval, multi-document answers, and multi-hop reasoning. These provide reproducible baselines.
Internal datasets from Dash usage. From logs, they created representative query sets (anonymized, ranked real queries) and representative content sets (popular files, docs, connected sources). From that content, they generated synthetic questions and answers using LLMs, covering tables, images, tutorials, and factual lookups.
Together, these datasets approximate the long tail of real usage in a reproducible form you can re-run in every experiment.
Layer 2: LLM-as-Judge Metrics
Classic metrics still run as quick sanity checks. But the core of the system is LLM-as-judge.
A judge model receives four inputs: the user query, the candidate answer from Dash, the retrieved context, and optionally a hidden reference answer. It scores specific dimensions:
{
“factual_accuracy”: 4,
“citation_correctness”: 1,
“clarity”: 5,
“formatting”: 4,
“explanation”: “Answer was accurate but referenced a source not in context.”
}Dropbox treats these judges like software modules: versioned, tuned against small human-labeled calibration sets, and periodically re-checked for agreement with human evaluators.
Key insight: Evaluating the evaluators becomes part of the loop. Judge models can drift or develop blind spots. Periodic human spot-checks keep them calibrated.
Layer 3: Evaluation Platform as CI
The platform works like CI for LLM behavior. A central store holds datasets and judge configurations. An orchestrator runs suites against any pipeline version or prompt template.
The test pyramid:
Pull requests — Fast regression subset, blocks merge on failures
Staging and nightly — Full curated suites
Production — Sampled live traffic re-run through judges to monitor drift
The same evaluation logic runs everywhere, giving consistency and traceability across experiments and releases.
Enforcement Levels
Not all metrics are equal. Dropbox separates them into three tiers:
Boolean gates — Hard fails. Examples: “citations present”, “source file exists”. A single failure blocks deployment.
Scalar budgets — Thresholds that cannot regress. Examples: minimum source F1, p95 latency ceiling, cost per query. Changes that degrade these are blocked.
Rubric scores — Softer properties like tone, narrative quality, formatting. Tracked in dashboards but do not block deployment.
This separation prevents promising experiments from being blocked by minor rubric regressions while still protecting users from factuality and citation failures.
Trade-offs
Dropbox’s choices came with clear trade-offs.
LLM judges add cost and drift risk. They provide flexibility: you can encode complex rubrics and adapt to new tasks without training task-specific scorers. But they are another model that can degrade. Dropbox uses smaller, specialized judge models when possible and relies on human spot-checks for calibration.
CI integration slows iteration. Wiring evaluations into every pull request increases reliability but can bottleneck development if suites are too heavy. Dropbox addresses this with the test pyramid: tiny fast subsets for PRs, full suites for staging and nightly runs.
Hard gates can block good changes. A change might hurt one metric while improving others. Separating boolean gates, scalar budgets, and rubric scores gives flexibility. Safety-critical dimensions block; UX dimensions inform.
Requires representative data. This approach assumes you can collect internal usage data and have some human labeling capacity. In domains with sparse data or strict privacy rules, you may need heavier reliance on public datasets and synthetic generation.
When This Pattern Applies
Use evaluation-as-infrastructure when:
Your LLM system has multiple interacting stages (retrieval, ranking, generation)
Quality is multi-dimensional (accuracy, citations, latency, cost)
You need to gate deployments on behavior, not just unit tests
Multiple engineers iterate on prompts, models, and retrievers in parallel
You have access to representative usage data or can generate synthetic queries
You can skip this complexity when:
Your LLM usage is simple (single prompt, no retrieval)
Quality can be measured with a single metric
You have low deployment frequency and can manually review each change
The Takeaway
Dropbox’s work on Dash shows that for LLM applications, evaluation is core system design, not an afterthought. By curating realistic datasets, using LLMs as structured judges, and wiring evaluations into CI and production, they turned a fragile text box into a monitored, testable system.
The patterns connect directly to classic system design: test pyramids, observability, deployment gates. The difference is that LLM behavior is probabilistic, so your checks must be probabilistic too. Treat datasets as versioned assets. Design judge prompts as reusable modules. Wrap your pipeline in an evaluation platform that can say no to unsafe changes.
Reference: A practical blueprint for evaluating conversational AI at scale.
Learn more about ML System Design @ System Overflow