
How OpenAI Runs ChatGPT on a Single PostgreSQL Primary
One primary, 50 read replicas, 800 million users. Here’s what makes it work.

Most engineers assume that at OpenAI’s scale, you’d need a distributed database. Sharded Postgres, CockroachDB, or Spanner. Something designed from the ground up for horizontal scaling.
OpenAI runs ChatGPT on a single PostgreSQL primary with 50 read replicas. One writer handling all writes for 800 million users.
Understanding why this works reveals something important about database scaling: the bottleneck you assume you have often isn’t the bottleneck you actually have.
Why Single-Primary Can Work
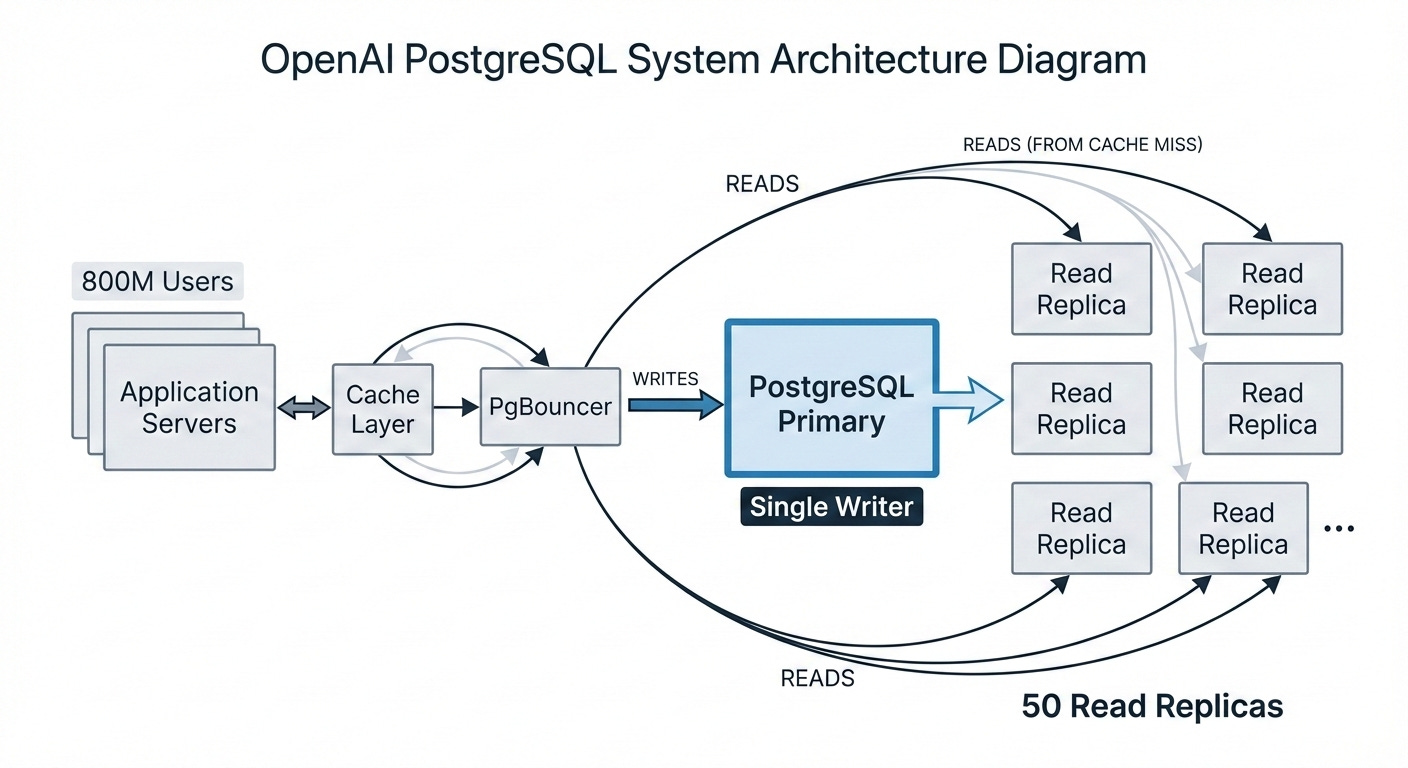
The key insight is that ChatGPT’s workload is overwhelmingly read-heavy. Users send messages, but the system reads far more than it writes: fetching conversation history, loading user preferences, checking permissions, retrieving model configurations.
For read-heavy workloads, you don’t need to distribute writes. You need to distribute reads. And PostgreSQL’s streaming replication makes this straightforward: one primary handles all writes, and up to 50 read replicas serve read traffic across multiple geographic regions.
The math: With an overwhelmingly read-heavy workload and 50 replicas, each replica handles only a fraction of total read traffic. The primary focuses on writes. This is a fundamentally different scaling model than trying to distribute writes across shards.
This architecture delivers low double-digit millisecond p99 latency and five-nines availability. In the past 12 months, OpenAI has had exactly one SEV-0 PostgreSQL incident, and that was during the ImageGen launch when 100 million new users signed up in a single week.
The Real Bottlenecks
If single-primary works so well, why doesn’t everyone do it? Because making it work requires solving problems that most teams never encounter at smaller scale.
Connection limits. Azure PostgreSQL maxes out at 5,000 connections per instance. With hundreds of application servers, each maintaining connection pools, you hit this limit fast. OpenAI solved this with PgBouncer, a connection pooler that sits between applications and PostgreSQL. In transaction pooling mode, connections are returned to the pool after each transaction, allowing thousands of application connections to share hundreds of database connections. This dropped average connection time from 50ms to 5ms.
Cache miss storms. OpenAI uses a caching layer to serve most reads. But when cache hit rates drop unexpectedly, the burst of misses can overwhelm PostgreSQL. Their solution: cache locking. When multiple requests miss on the same cache key, only one request fetches from the database. The others wait for the cache to be repopulated. This prevents a single cache failure from cascading into a database outage.
Expensive queries. One 12-table join was responsible for multiple high-severity incidents. A spike in this single query could saturate CPU and slow down the entire service. The fix wasn’t just optimizing the query. It was recognizing that complex joins are an anti-pattern for OLTP workloads. If you need a 12-way join, break it into smaller queries and join in the application layer. Also: never trust your ORM. Always review the SQL it generates.
PostgreSQL’s MVCC Problem
While reads scale well, writes expose PostgreSQL’s fundamental limitation: its multiversion concurrency control (MVCC) implementation.
When you update a row in PostgreSQL, even a single field, the database doesn’t modify the existing row. It copies the entire row to create a new version. The old version becomes a “dead tuple” that remains in the table until vacuum cleans it up.
The cascade effect: Write amplification means you’re writing more data than you think. Dead tuples mean reads must scan past obsolete versions. Tables and indexes bloat, consuming more storage and slowing queries. Autovacuum struggles to keep up under heavy write loads, requiring careful tuning.
This is why OpenAI doesn’t try to scale writes on PostgreSQL. Instead, they’ve migrated write-heavy workloads to sharded systems like Azure CosmosDB. The workloads that remain on PostgreSQL are ones where read-heavy patterns make the single-primary architecture viable.
They’ve also banned adding new tables to PostgreSQL entirely. New features must use the sharded systems by default. This prevents the gradual accumulation of write-heavy workloads that would eventually overwhelm the primary.
Protecting the Primary
With only one writer, the primary is a single point of failure. OpenAI’s mitigation strategy has multiple layers.
Offload everything possible. Any read that doesn’t require transactional consistency with writes goes to a replica. This means that even if the primary fails, most user-facing requests continue working. Write failures are still serious, but the blast radius is smaller.
Hot standby. The primary runs in high-availability mode with a continuously synchronized standby ready to take over. Azure has optimized this failover to remain safe even under extremely high load.
Workload isolation. Requests are split into priority tiers and routed to separate instances. A new feature launch with inefficient queries won’t degrade the performance of critical requests. Different products are isolated from each other so that one product’s traffic spike doesn’t affect another.
Rate limiting everywhere. Limits are enforced at the application layer, connection pooler, proxy, and query level. The ORM layer can block specific query patterns entirely. When a surge of expensive queries hits, targeted load shedding allows rapid recovery without affecting other traffic.
Scaling Read Replicas
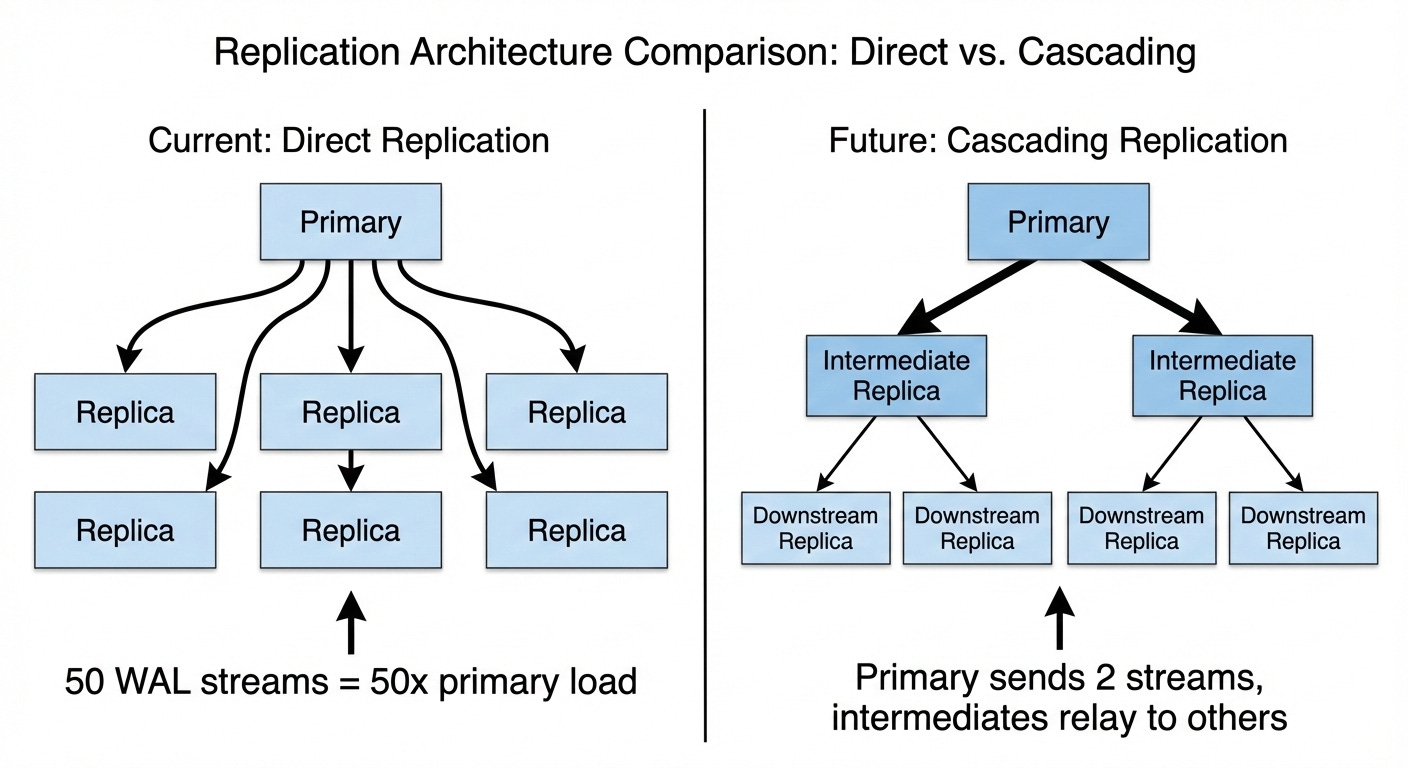
Adding read replicas seems simple: spin up more instances, point them at the primary, done. At OpenAI’s scale, it’s more complicated.
The primary streams Write Ahead Log (WAL) data to every replica. With 50 replicas, that’s 50 separate streams consuming network bandwidth and CPU on the primary. Each additional replica adds more pressure. You can’t scale replicas indefinitely without eventually overwhelming the writer you’re trying to protect.
OpenAI is working with Azure on cascading replication, where intermediate replicas relay WAL to downstream replicas instead of every replica connecting directly to the primary. This would allow scaling to over 100 replicas without proportionally increasing primary load. But it adds operational complexity around failover management, so it’s still in testing.
Schema Changes at Scale
In a normal PostgreSQL deployment, you might run ALTER TABLE without much thought. At OpenAI’s scale, schema changes are a production risk.
Some seemingly minor changes, like altering a column type, trigger a full table rewrite. The database locks the table, copies every row to a new version with the updated schema, then swaps the tables. For a table with billions of rows, this can take hours and block writes the entire time.
OpenAI’s rules are strict:
Only lightweight schema changes are permitted (adding nullable columns, dropping columns that don’t trigger rewrites)
Schema changes have a 5-second timeout. If it can’t complete in 5 seconds, it fails.
Index creation must use CONCURRENTLY to avoid locking
Backfilling table fields is rate-limited. Filling a new column can take over a week, but it doesn’t impact production.
When This Architecture Breaks Down
OpenAI’s approach works because their workload matches specific assumptions. Change those assumptions, and the architecture fails.
Write-heavy workloads don’t fit. If your application is 50% writes instead of 5% writes, a single primary becomes the bottleneck immediately. You need sharding or a database designed for distributed writes.
Strong consistency requirements complicate reads. Reading from replicas means accepting replication lag. If your application requires reading your own writes immediately, those reads must go to the primary, reducing the benefit of replicas.
Operational complexity is high. Managing 50 replicas across multiple regions, tuning PgBouncer, implementing cache locking, enforcing query patterns, rate limiting at every layer: this requires significant engineering investment. For smaller teams, a managed distributed database might be simpler even if it’s theoretically less efficient.
The Deeper Lesson
OpenAI’s PostgreSQL architecture isn’t a universal template. It’s an example of matching architecture to workload characteristics.
They could have sharded from the start. Many engineers would have assumed sharding was necessary at their scale. Instead, they analyzed their actual workload, recognized it was read-heavy, and built an architecture optimized for that pattern. The result is simpler than a sharded system (one writer, no distributed transactions, no cross-shard queries) while still handling 800 million users.
The lesson isn’t that sharding is bad or that single-primary is always better. It’s that scaling decisions should be driven by workload analysis, not assumptions about what “web scale” requires. The architecture that works depends on your read/write ratio, consistency requirements, query patterns, and team capacity.
Sometimes the boring solution, PostgreSQL with read replicas, scales further than you’d expect. You just have to solve the right problems.
Source: Scaling PostgreSQL to 800 Million Users - OpenAI Engineering Blog
Learn more about database scaling and system design @ System Overflow