
TPUs: The Chip That Trades Flexibility for Raw ML Performance
The $100 Million Question Nobody Asked

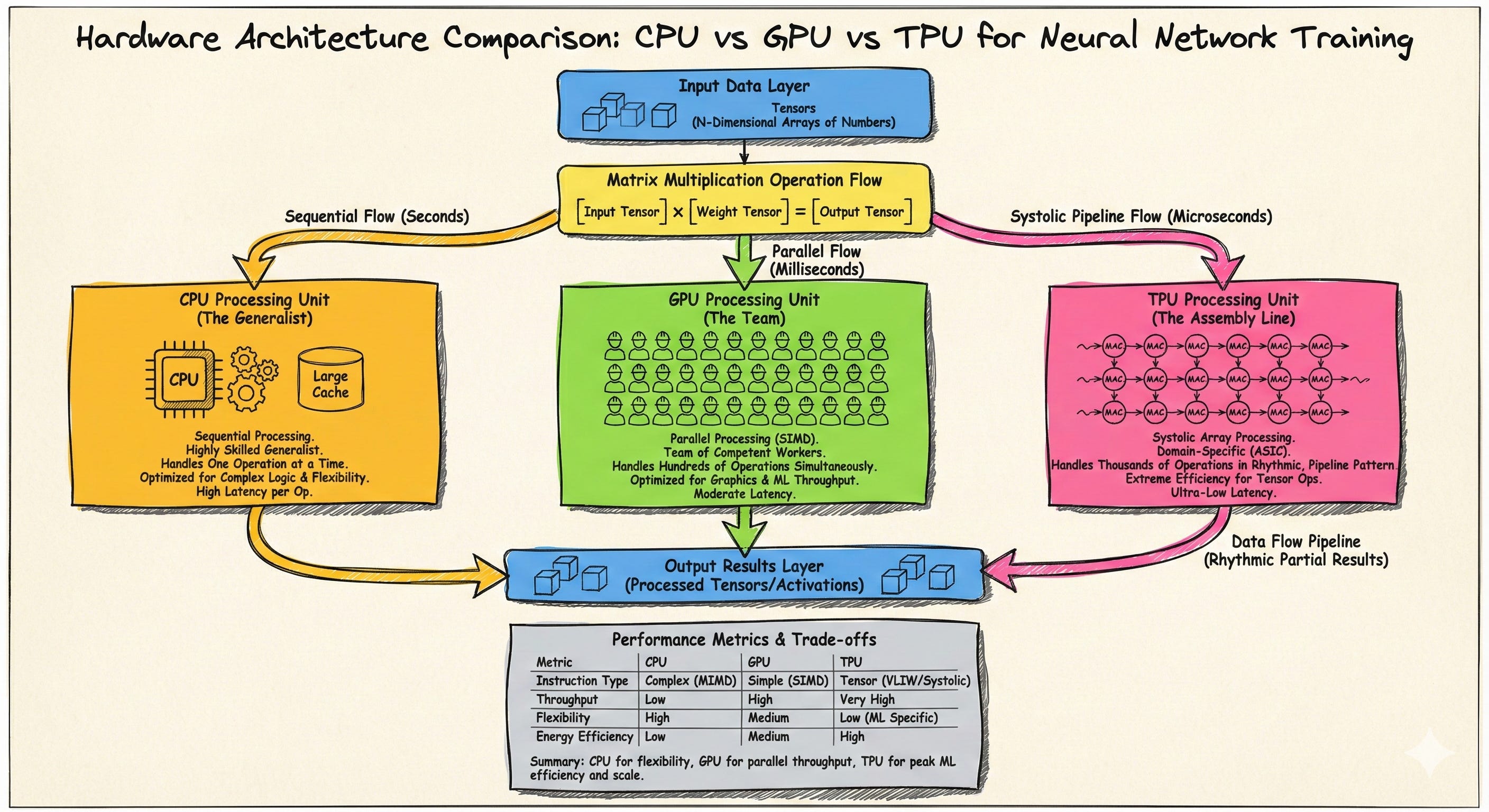
Most engineers think of TPUs as “Google’s GPUs.” They’re not. TPUs represent a fundamentally different design philosophy: instead of building flexible hardware that handles many workloads adequately, Google built specialized hardware that handles one workload exceptionally.
To understand TPUs, we need to start with a question: what do neural networks actually do at the hardware level?
The Problem TPUs Solve
Neural network training and inference are dominated by one operation: matrix multiplication. Forward pass? Multiply weight matrices by activation vectors. Backpropagation? More matrix multiplies to compute gradients. Attention mechanisms? Matrix multiplies between queries, keys, and values.
GPUs handle this reasonably well because they’re designed for parallel computation. But GPUs are also designed to run graphics, physics simulations, cryptocurrency mining, and general-purpose computing. All that flexibility comes with overhead: complex instruction decoding, cache hierarchies for unpredictable memory access, branch prediction for conditional code.
Google asked: what if we threw all that away and built hardware that only does matrix multiplication?
The Systolic Array: TPU’s Core Innovation
The answer is the systolic array, a computing architecture from the 1980s that fell out of favor for general computing but turns out to be perfect for matrix math.
Picture a two-dimensional grid of simple processing elements. Each cell does exactly one thing: multiply two numbers and add the result to a running total. No conditionals, no branching, no complex logic.
How data flows: Weights load into the array and stay stationary. Activations flow in from the left, moving one cell right each clock cycle. Partial sums flow downward. By the time data exits the bottom of the array, you have your matrix multiplication result.
The term “systolic” comes from the heart. Just as blood pulses through your circulatory system in waves, data pulses through the array in a regular, predictable rhythm.
This predictability is the key insight. Because data flow is fixed, the hardware never waits for memory, never mispredicts a branch, never stalls on a cache miss. Every cycle, every cell is doing useful work.
Even better, each value gets reused multiple times. A weight sitting in a cell multiplies against every activation that flows past it. An activation moving across a row multiplies against every weight in that row. This data reuse dramatically reduces memory bandwidth requirements.
What TPUs Give Up
This efficiency comes from extreme specialization. Understanding what TPUs can’t do is just as important as understanding what they excel at.
No general-purpose computing. TPUs can’t run arbitrary code. They only execute tensor operations. Anything else, from data preprocessing to custom logic, runs on a host CPU and communicates with the TPU over PCIe.
No CUDA, no direct programming. You don’t write TPU kernels. Instead, you write TensorFlow or JAX code, and the XLA (Accelerated Linear Algebra) compiler transforms it into TPU instructions. This means automatic optimization, but also less control when things don’t compile efficiently.
No flexibility on precision. TPUs are designed around bfloat16, a 16-bit format optimized for ML. This works well for neural networks, but if your workload needs higher precision, you’re fighting the hardware.
No purchasing or on-prem deployment. TPUs are cloud-only, rented from Google Cloud. You can’t buy them for your own datacenter.
How This Compares to GPUs
Now that we understand how TPUs work, the comparison to GPUs becomes clearer. These aren’t just different products; they’re different philosophies.
Parallelism model — GPUs use SIMT (Single Instruction, Multiple Threads): thousands of threads executing the same instruction on different data. TPUs use systolic data flow: values streaming through a fixed grid. SIMT handles irregular workloads gracefully; systolic arrays maximize efficiency for regular workloads.
Memory architecture — GPUs use complex cache hierarchies to hide unpredictable memory latency. TPUs use large on-chip buffers with predictable access patterns, eliminating caching overhead entirely.
Programmability — GPUs let you write custom CUDA kernels with fine-grained control. TPUs require compilation through XLA, which optimizes automatically but limits what you can express.
Ecosystem — CUDA has 15+ years of libraries, tools, and community knowledge. TPU tooling is younger and entirely controlled by Google.
Neither approach is universally better. They optimize for different assumptions about your workload.
Programming TPUs: The XLA Model
Since you can’t program TPUs directly, understanding XLA is essential.
XLA captures your computation as a graph of operations: matrix multiplies, convolutions, activations, and so on. It then optimizes this graph by fusing operations together, eliminating redundant computation, and arranging memory layout for efficient access. Finally, it generates TPU instructions that map onto the systolic array.
The trade-off: XLA handles optimization automatically, but you lose the ability to hand-tune performance. If an operation compiles poorly, your options are limited compared to CUDA, where you can always write a custom kernel.
This is why TPUs work best with standard architectures. Transformers, CNNs, and common layer types compile efficiently. Custom operations or unusual control flow can hit XLA limitations.
Practical Considerations: Batch Size and Memory
TPUs have a simpler memory hierarchy than GPUs: High Bandwidth Memory (HBM) connects to on-chip buffers, which feed the systolic array. The key constraint is keeping the array fed with data.
This is why batch size matters enormously on TPUs. Larger batches mean more data reuse in the systolic array, better amortization of memory transfer overhead, and higher utilization of compute units. If your batch size is too small, the array spends cycles waiting for data instead of computing.
This differs from GPUs, where the flexible threading model handles small batches more gracefully. On TPUs, you often need to redesign your training pipeline around larger batches to achieve good performance.
When TPUs Struggle
The systolic array’s efficiency comes from predictable, dense, regular computation. When workloads deviate from this pattern, performance degrades.
Sparse operations are the clearest example. If your matrices are mostly zeros, the systolic array still processes every zero. There’s no sparse matrix acceleration. Sparse attention mechanisms, mixture-of-experts with dynamic routing, or sparse activations can significantly underutilize TPU hardware.
Dynamic shapes cause problems because XLA compiles for specific tensor dimensions. Variable sequence lengths or dynamic batching require either padding (wasting compute) or recompilation (adding latency).
Complex control flow maps poorly to the systolic array’s fixed data flow. Most neural networks are straight-line computation, but models with significant branching can struggle.
Scaling: TPU Pods
Individual TPUs connect into pods through high-speed custom interconnects. Unlike GPU clusters that use standard InfiniBand or Ethernet, TPU pods use a 2D or 3D torus topology where each chip communicates directly with its neighbors.
This topology is optimized for the communication patterns of distributed ML training, particularly the all-reduce operations used in gradient synchronization. The interconnect is tightly coupled with the TPU architecture, rather than being a separate networking layer you configure independently.
This tight coupling means TPU pods can be extremely efficient for workloads that fit their communication patterns, but less flexible if your distributed training approach differs from Google’s assumptions.
Making the Choice
Given everything above, here’s when each option makes sense:
Choose GPUs when:
You need framework flexibility, especially PyTorch-first workflows
Your workloads include sparse operations or dynamic shapes
You want multi-cloud or on-premises deployment
You need fine-grained control over kernel implementations
You’re prototyping and need fast iteration
Choose TPUs when:
You’re running large-scale training or inference on dense, regular models
You’re using TensorFlow or JAX and standard architectures
You can use large batch sizes that saturate the systolic array
Latency predictability matters (TPUs don’t thermal throttle like GPUs)
You’re committed to Google Cloud infrastructure
The Broader Lesson
TPUs embody a bet: that ML workloads are important and stable enough to justify specialized silicon. General-purpose hardware can run anything but excels at nothing. Specialized hardware excels at specific workloads but becomes useless when requirements change.
So far, Google’s bet has paid off. The workloads that matter most, transformers and large language models, are exactly the dense matrix operations that systolic arrays handle best.
The lesson for engineers isn’t that TPUs are better or worse than GPUs. It’s that hardware architecture embodies assumptions about workloads. When you understand those assumptions, you can match your problem to the right hardware. When you don’t, you end up fighting the architecture instead of leveraging it.
Dive deeper into ML System Design @ System Overflow
Thanks for writing this, it clarifies a lot. It’s truly amazing how focusing on just matrix multiplication with a systolic array can unlock such imense power. What a clever design!